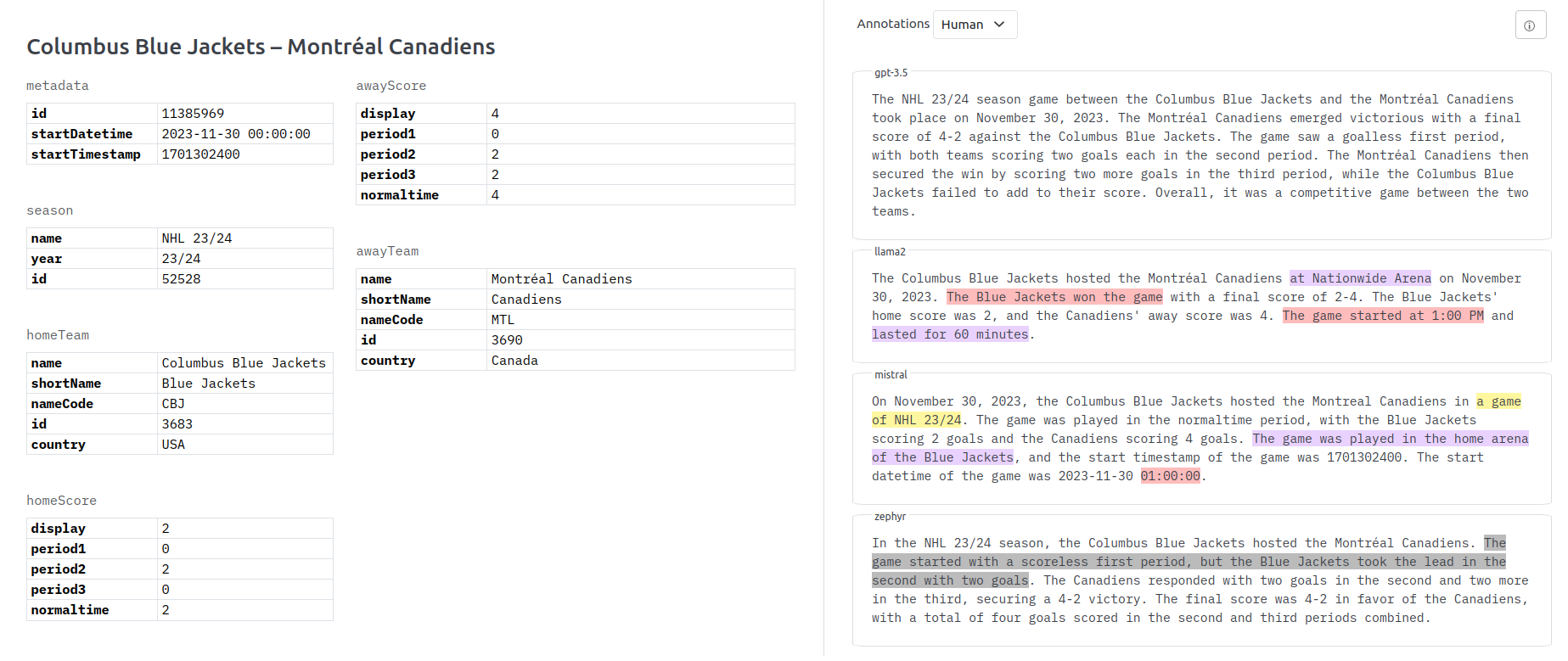
Ice hockey game summary.
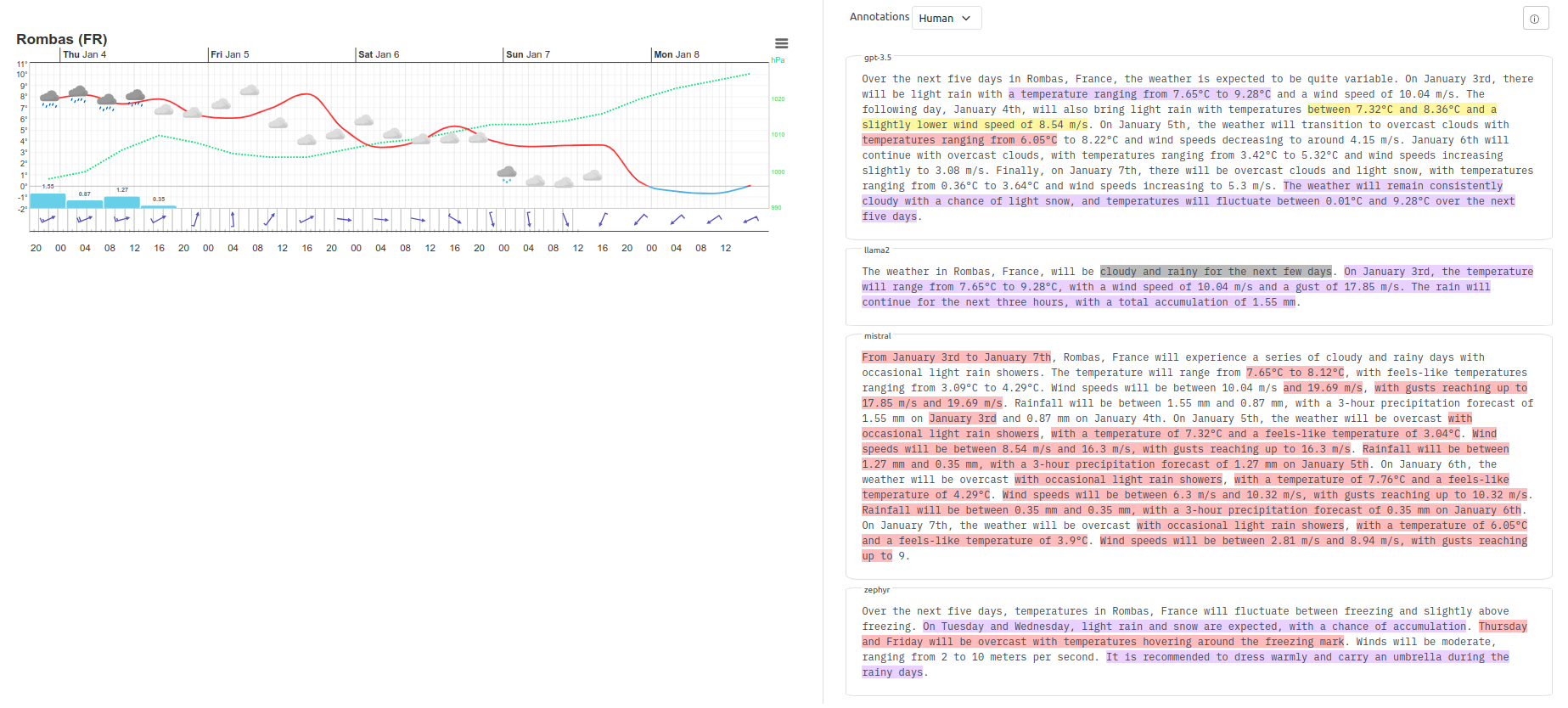
5-day weather forecast.
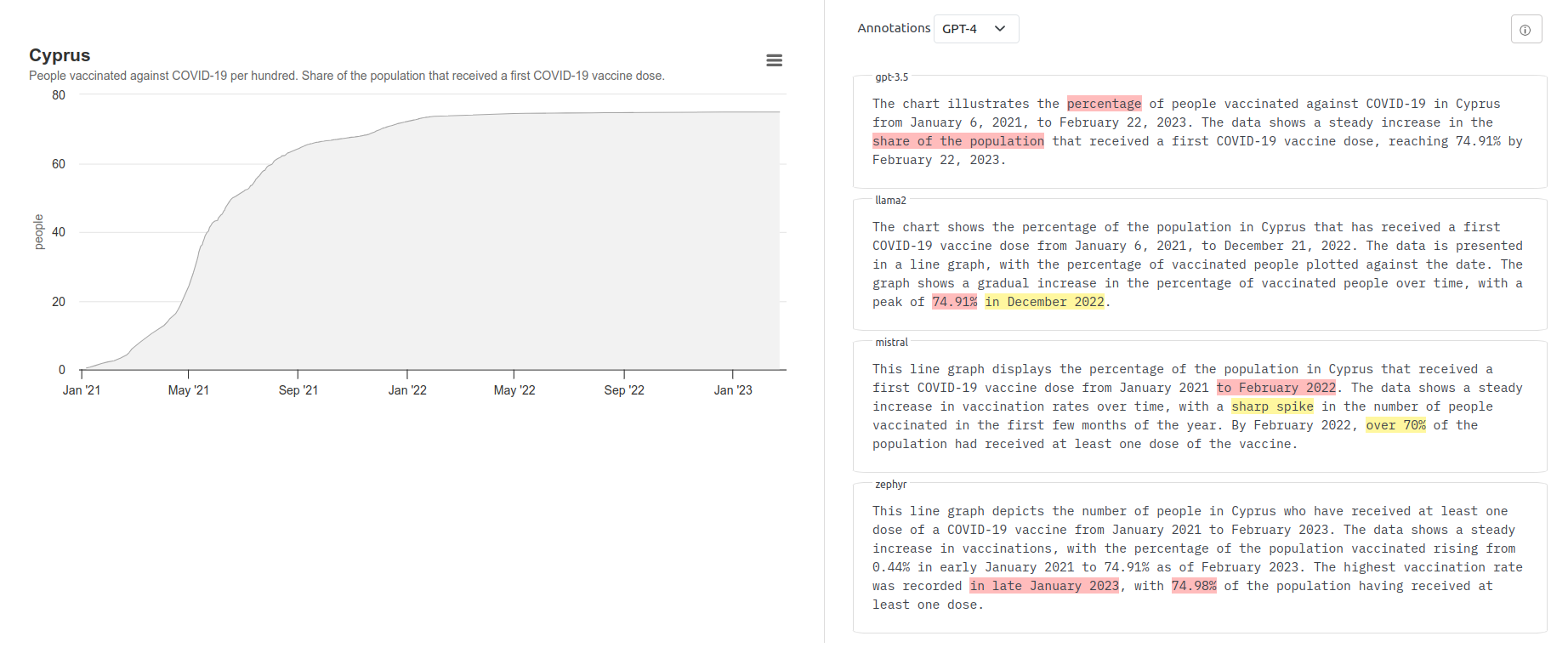
We analyze the behaviors of open large language models (LLMs) on the task of data-to-text (D2T) generation, i.e., generating coherent and relevant text from structured data. To avoid the issue of LLM training data contamination with standard benchmarks, we design Quintd - a tool for collecting novel structured data records from public APIs. We find that open LLMs (Llama 2, Mistral, and Zephyr) can generate fluent and coherent texts in zero-shot settings from data in common formats collected with Quintd. However, we show that the semantic accuracy of the outputs is a major issue: both according to human annotators and our reference-free metric based on GPT-4, more than 80% of the outputs of open LLMs contain at least one semantic error. We publicly release the code, data, and model outputs.
@inproceedings{kasner2024beyond,
title = "Beyond Traditional Benchmarks: Analyzing Behaviors of Open {LLM}s on Data-to-Text Generation",
author = "Kasner, Zden{\v{e}}k and
Du{\v{s}}ek, Ond{\v{r}}ej",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.651",
pages = "12045--12072",
}